目标地址
https://match.yuanrenxue.com/match/3
任务3:抓取下列5页商标的数据,并将出现频率最高的申请号填入答案中
分析过程
使用无痕模式, 避免无关的因素影响
第一次访问会出现, 然后会跳转到首页
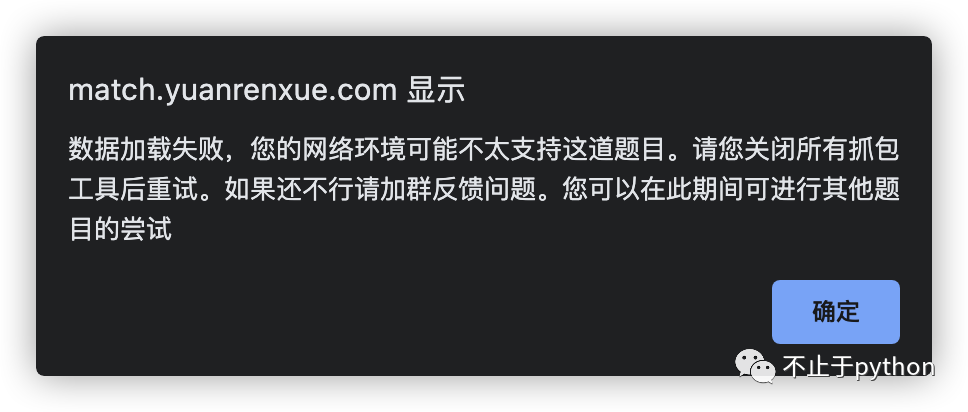
从首页进去点进去发现提示没有了, 然后我们翻页看一下请求
除了页数page会变化外, 还会发现, 每次请求之前会先请求一下
https://match.yuanrenxue.com/jssm
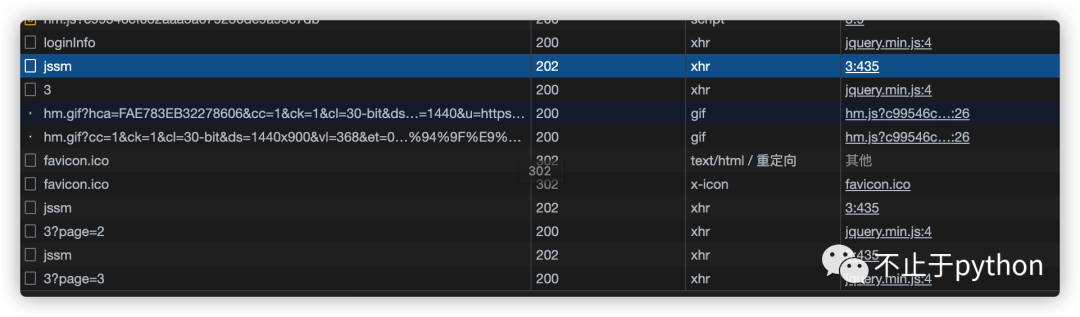
先不管这个jssm, 直接复制page的curl请求一下试试
发现返回了一段js
复制到控制台执行一下, 发现并没有什么用, 页面的信息也没有什么变化, 是一个 undefined
看来跟另外一个请求jssm有关, 看一下这个jssm干了什么, 分析后发现
jssm没有响应内容, 只是会设置上一个cookie, 后面的请求page数据会带上这个cookie, 看来就是这个cookie的问题了
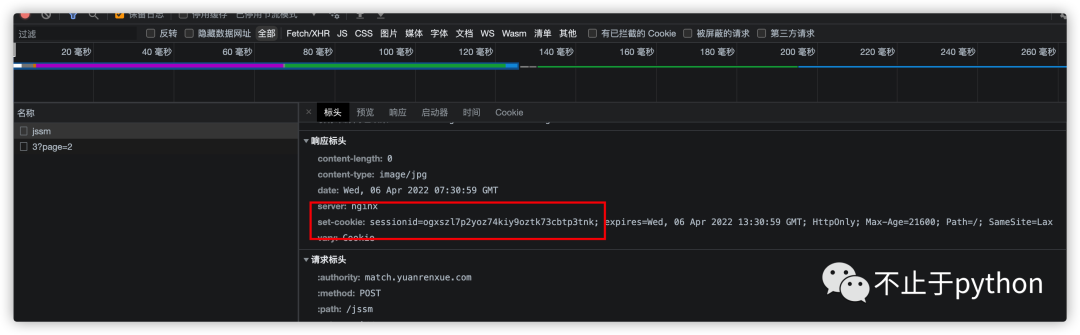
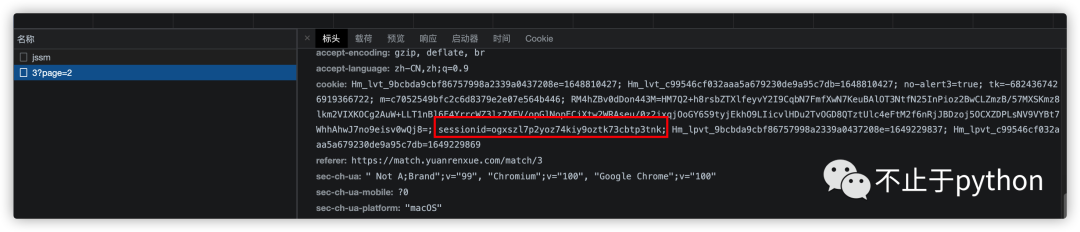
现在我们只需要把jssm的响应cookie拿到, 并且在请求page数据时带上应该就可以了
复制curl, 转为python, 测试, 打印一下响应cookie, 发现是空
这看起来跟浏览器一样呀, 所有的headers cookie啥的, 使用抓包工具试一下
打开后, 看一下请求, 对比headers,cookie后发现了一点问题
headers的请求顺序变了, 难道跟这个有关系? 复制出来再试试
结果发现还是空, 这就说明headers的请求顺序还是不正确, 但是一项项对比完之后, 确实是没有问题的, 后来看了一下requests的源码, 发现requests会对headers再次处理, 而字典是无序的, 所以只需要保证headers是有序的, 在requests处理时顺序不会变化即可
将headers改一下, 写成类是因为requests要使用headers的items方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| class headers:
@staticmethod
def items():
return (
('content-length','0'),
('sec-ch-ua','" Not A;Brand";v="99", "Chromium";v="100", "Google Chrome";v="100"'),
('sec-ch-ua-mobile','?0'),
('user-agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36'),
('sec-ch-ua-platform','"macOS"'),
('accept','*/*'),
('origin','https://match.yuanrenxue.com'),
('sec-fetch-site','same-origin'),
('sec-fetch-mode','cors'),
('sec-fetch-dest','empty'),
('referer','https://match.yuanrenxue.com/match/3'),
('accept-encoding','gzip, deflate, br'),
('accept-language','zh-CN,zh;q=0.9'),
('cookie','Hm_lvt_9bcbda9cbf86757998a2339a0437208e=1648810427'),
('cookie','Hm_lvt_c99546cf032aaa5a679230de9a95c7db=1648810427'),
('cookie','no-alert3=true'),
('cookie','tk=-6824367426919366722'),
('cookie','m=c7052549bfc2c6d8379e2e07e564b446'),
('cookie','RM4hZBv0dDon443M=HM7Q2+h8rsbZTXlfeyvY2I9CqbN7FmfXwN7KeuBAlOT3NtfN25InPioz2BwCLZmzB/57MXSKmz8lkm2VIXKOCg2AuW+LLT1nBl6E4YrrcWZ3lz7XEV/opGlNopECiXtw2WRAseu/0z2ixqjOoGY6S9tyjEkhO9LIicvlHDu2TvOGD8QTztUlc4eFtM2f6nRjJBDzoj5OCXZDPLsNV9VYBt7WhhAhwJ7no9eisv0wQj8='),
('cookie','sessionid=ogxszl7p2yoz74kiy9oztk73cbtp3tnk'),
('cookie','Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=1649229837'),
('cookie','Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=1649229869'),
)
|
这次会发现可以返回响应cookie了
1
| <RequestsCookieJar[<Cookie sessionid=pfdmiz5h3eppxkhtktgcsrfu6ozcokvf for match.yuanrenxue.com/>]>
|
而请求page页数据, 需要使用这个cookie, 只需要使用requests的session即可, 同理page页的headers也需要排序, 优化后的源代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| # -*- coding: utf-8 -*-
import requests
session = requests.Session()
class headers(object):
@staticmethod
def items():
return (
("content-length", "0"),
("accept", "*/*"),
("referer", "https://match.yuanrenxue.com/match/3"),
("accept-encoding", "gzip, deflate, br"),
("accept-language", "zh-CN,zh;q=0.9"),
("cookie", "no-alert3=true"),
)
class theaders(object):
@staticmethod
def items():
return (
('accept', 'application/json, text/javascript, */*; q=0.01'),
('referer', 'https://match.yuanrenxue.com/match/3'),
('accept-encoding', 'gzip, deflate, br'),
('accept-language', 'zh-CN,zh;q=0.9'),
('user-agent', 'yuanrenxue.project'),
)
def main():
value_map = {}
for page in range(1, 6):
r = session.post('https://match.yuanrenxue.com/jssm', headers=headers, verify=False)
print(r.cookies)
params = (
('page', page),
)
response = session.get('https://match.yuanrenxue.com/api/match/3', headers=theaders, params=params)
for value in response.json()["data"]:
if value["value"] in value_map:
value_map[value["value"]] += 1
else:
value_map[value["value"]] = 1
value_count = sorted(value_map.items(), key=lambda x:x[1], reverse=True)
return value_count[0][0]
print(main())
|