1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
| # -*- coding: utf-8 -*-
# @Author: Mehaei
# @Date: 2020-01-10 14:51:53
# @Last Modified by: Mehaei
# @Last Modified time: 2020-01-13 10:10:13
import re
import os
import requests
from lxml import etree
from fontTools.ttLib import TTFont
class NotFoundFontFileUrl(Exception):
pass
class CarHomeFont(object):
def __init__(self, url, *args, **kwargs):
self.local_ttf_name = "norm_font.ttf"
self.download_ttf_name = 'new_font.ttf'
self.new_unicode_map = {}
self._making_local_code_map()
self._download_ttf_file(url, self.download_ttf_name)
def _download_ttf_file(self, url, file_name):
self.page_html = self.download(url) or ""
# 获取字体的连接文件
font_file_name = (re.findall(r",url\('(//.*\.ttf)?'\) format", self.page_html) or [""])[0]
if not font_file_name:
raise NotFoundFontFileUrl("not found font file name")
# 下载字体文件
file_content = self.download("https:%s" % font_file_name, content=True)
# 讲字体文件保存到本地
with open(file_name, 'wb') as f:
f.write(file_content)
print("font file download success")
def _making_local_code_map(self):
if not os.path.exists(self.local_ttf_name):
# 这个url为标准字体文件地址, 如要更改, 请手动更改字体列表
url = "https://club.autohome.com.cn/bbs/thread/62c48ae0f0ae73ef/75904283-1.html"
self._download_ttf_file(url, self.local_ttf_name)
self.local_utf_word_map, self.local_utf_coordinates_map = self.extract_ttf_file(self.local_ttf_name)
print("local ttf load done")
def get_distence(self, norm_coordinate, new_coordinate):
distance_total = 0
for index, coordinate_point in enumerate(norm_coordinate):
distance_total += abs(new_coordinate[index][0] - coordinate_point[0]) + abs(new_coordinate[index][1] - coordinate_point[1])
return distance_total
def handle_subtraction(self, coordinate_equal_list):
coordinate_min_list = []
for coordinate_equal in coordinate_equal_list:
n = self.get_distence(coordinate_equal.get('norm_coordinate'), coordinate_equal.get('new_coordinate'))
coordinate_min_list.append(n)
return coordinate_equal_list[coordinate_min_list.index(min(coordinate_min_list))]
def replace_ttf_map(self):
unicode_mlist_map = []
new_utf_coordinates_map = self.extract_ttf_file(self.download_ttf_name, get_word_map=False)
for local_unicode, local_coordinate in self.local_utf_coordinates_map.items():
coordinate_equal_list = []
for new_unicode, new_coordinate in new_utf_coordinates_map.items():
if len(new_coordinate) == len(local_coordinate):
coordinate_equal_list.append({"norm_key": local_unicode, "norm_coordinate": local_coordinate, "new_key": new_unicode, "new_coordinate": new_coordinate})
if len(coordinate_equal_list) == 1:
unicode_mlist_map.append(coordinate_equal_list[0])
elif len(coordinate_equal_list) > 1:
min_word = self.handle_subtraction(coordinate_equal_list)
unicode_mlist_map.append(min_word)
for unicode_dict in unicode_mlist_map:
self.new_unicode_map[unicode_dict["new_key"]] = self.local_utf_word_map[unicode_dict["norm_key"]]
print("new unicode map extract success\n", self.new_unicode_map)
def extract_ttf_file(self, file_name, get_word_map=True):
_font = TTFont(file_name)
uni_list = _font.getGlyphOrder()[1:]
# 被替换的字体的列表
word_list = [
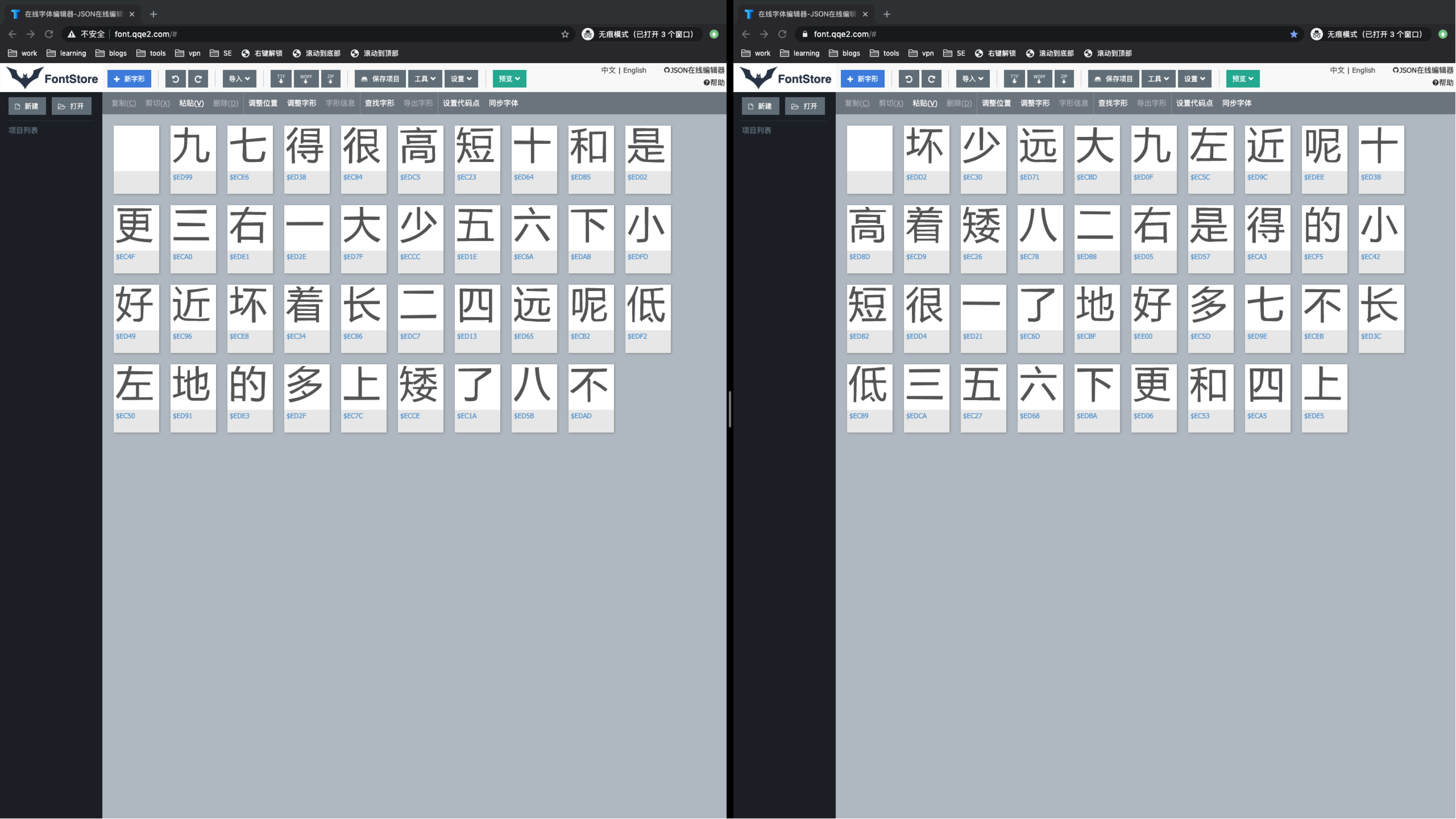
"坏", "少", "远", "大", "九", "左", "近", "呢", "十", "高", "着",
"矮", "八", "二", "右", "是", "得", "的", "小", "短", "很", "一", "了",
"地", "好", "多", "七", "不", "长", "低", "三", "五", "六", "下", "更",
"和", "四", "上"
]
utf_word_map = {}
utf_coordinates_map = {}
for index, uni_code in enumerate(uni_list):
utf_word_map[uni_code] = word_list[index]
utf_coordinates_map[uni_code] = list(_font['glyf'][uni_code].coordinates)
if get_word_map:
return utf_word_map, utf_coordinates_map
return utf_coordinates_map
def repalce_source_code(self):
replaced_html = self.page_html
for utf_code, word in self.new_unicode_map.items():
replaced_html = replaced_html.replace("&#x%s;" % utf_code[3:].lower(), word)
return replaced_html
def get_subject_content(self):
normal_html = self.repalce_source_code()
# 使用xpath 获取 主贴
xp_html = etree.HTML(normal_html)
subject_text = ''.join(xp_html.xpath('//div[@xname="content"]//div[@class="tz-paragraph"]//text()'))
return subject_text
def download(self, url, *args, try_time=5, method="GET", content=False, **kwargs):
kwargs.setdefault("headers", {})
kwargs["headers"].update({"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"})
while try_time:
try:
response = requests.request(method.upper(), url, *args, **kwargs)
if response.ok:
if content:
return response.content
return response.text
else:
continue
except Exception as e:
try_time -= 1
print("download error: %s" % e)
if __name__ == "__main__":
url = "https://club.autohome.com.cn/bbs/thread/34d6bcc159b717a9/85794510-1.html#pvareaid=6830286"
car = CarHomeFont(url)
car.replace_ttf_map()
text = car.get_subject_content()
print(text)
|