爬虫过程中需要注意的问题-不止于python
一.存储数据库
1.问题:
当保存指定字段存入数据库的时候,如果仔细查看数据库会发现,主键id是不连续的值,即使设置了失败后事务回滚,也无济于事
也就是说,不管数据是否插入成功,id都会自增1
原因:
innodb的自增是缓存在内存字典中的,分配方式是先预留,然后再插入的。所以插入失败不会回滚内存字典
解决:
让innodb识别到当前最大id的方法是重启server 更新AUTO_INCREMENT缓存
在插入失败的时候,将主键重新赋值为1,数据库就会将下一个自增id设置为当前表中最大的id加1
1 | alter table haowai auto_increment=1 #haowai只是表名 |
例:scrapy框架的pipelines.py文件
1 | class HaowaiPipeline(object): |
二.请求百度首页返回一个错误的页面,如下:
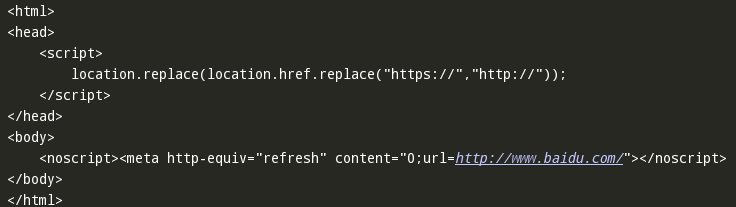
源代码如下:
1 | from urllib import request |
原来以为是ssl验证的问题,后来加上了也不对,最后竟然是一个请求头的事
修改后的源代码如下:
1 | from urllib import request |
添加请求头后,返回了百度首页
唉!·······
作者:
胖胖不胖
版权声明:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 不止于python
感谢您的支持,我会继续努力!

微信支付

支付宝
