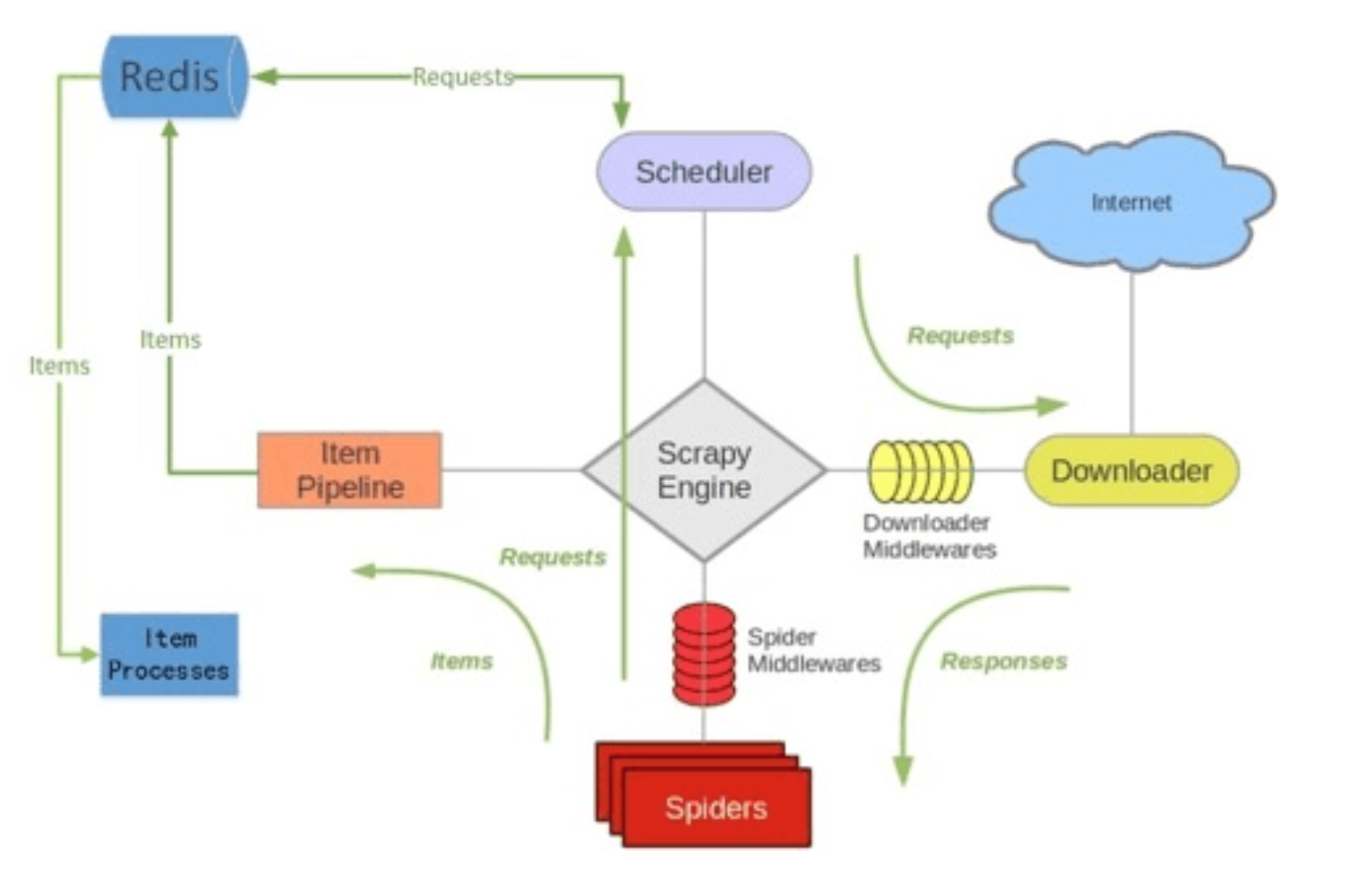
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
| import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_redis.spiders import RedisCrawlSpider
from scr_redis.items import LaGouItem
import re
import time
from datetime import datetime
from datetime import timedelta
class BaiduSpider(RedisCrawlSpider): #继承RedisCrawlSpider 类
name = 'lagou'
allowed_domains = ['lagou.com']
# start_urls = ['http://www.baidu.com/']
redis_key = 'start_url' #设置redis键名启动
rules = (
# Rule(LinkExtractor(allow=r''), callback='parse_item', follow=True),
# #搜索
Rule(LinkExtractor(allow=(r'lagou.com/jobs/list_',), tags=('form',), attrs=('action',)), follow=True),
# #公司招聘
Rule(LinkExtractor(allow=(r'lagou\.com/gongsi/',), tags=('a',), attrs=('href',)), follow=True),
# 公司列表
Rule(LinkExtractor(allow=(r'/gongsi/j\d+\.html',), tags=('a',), attrs=('href',)), follow=True),
# 校园招聘
Rule(LinkExtractor(allow=(r'xiaoyuan\.lagou\.com',), tags=('a',), attrs=('href',)), follow=True),
# 匹配校园分类
Rule(LinkExtractor(allow=(r'isSchoolJob',), tags=('a',), attrs=('href',)), follow=True),
# # 详情页
Rule(LinkExtractor(allow=(r'jobs/\d+\.html',), tags=('a',), attrs=('href',)), callback='parse_item',
follow=False),
)
num_pattern = re.compile(r'\d+') # 提取数字正则
custom_settings = {
'DEFAULT_REQUEST_HEADERS' : {
"Host": "www.lagou.com",
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Content-type": "application/json;charset=utf-8",
"Accept": "*/*",
"Referer": "https://www.lagou.com",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "user_trace_token=20171116192426-b45997e2-cac0-11e7-98fd-5254005c3644; LGUID=20171116192426-b4599a6d-cac0-11e7-98fd-5254005c3644; index_location_city=%E5%85%A8%E5%9B%BD; JSESSIONID=ABAAABAAAGFABEFC0E3267F681504E5726030548F107348; _gat=1; X_HTTP_TOKEN=d8b7e352a862bb108b4fd1b63f7d11a7; _gid=GA1.2.1718159851.1510831466; _ga=GA1.2.106845767.1510831466; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1510836765,1510836769,1510837049,1510838482; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1510839167; LGSID=20171116204415-da8c7971-cacb-11e7-930c-525400f775ce; LGRID=20171116213247-a2658795-cad2-11e7-9360-525400f775ce",
},
'COOKIES_ENABLED' : False,
'CONCURRENT_REQUESTS' : 5,
}
def parse_item(self, response):
item = LaGouItem()
title = response.css('span.name::text').extract()[0]
url = response.url
spans = response.xpath('//dd[@class="job_request"]//span')
salary = spans[0].css('span::text').extract()[0] #薪资
city =self.splits(spans[1].css('span::text').extract()[0])#工作城市
start,end= self.asks(self.splits(spans[2].css('span::text').extract()[0] ))#经验
edu = self.splits(spans[3].css("span::text").extract()[0] ) #学历
job_type = spans[4].css('span::text').extract()[0] #工作类型
label = "-".join(response.xpath('//ul[@class="position-label clearfix"]//li/text()').extract()) #标签
publish_time =self.times(response.xpath('//p[@class="publish_time"]//text()').extract()[0].strip('\xa0 发布于拉勾网')) #发布时间
tempy = response.xpath('//dd[@class="job-advantage"]//p/text()').extract()[0] #在职业诱惑
discription =''.join([''.join(i.split()) for i in response.xpath('//dd[@class="job_bt"]//div//text()').extract()]) #岗位职责
addr = '-'.join(response.xpath('//div[@class="work_addr"]//a/text()').extract()[:-1])
address = ''.join( ''.join(i.split()) for i in response.xpath('//div[@class="work_addr"]/text()').extract())
loction= addr+address #详细工作地址
#装载数据
item["title"] = title
item["url"] = url
item["salary"] = salary
item["city"] = city
item["start"] = start
item["end"] = end
item["edu"] = edu
item["job_type"] = job_type
item["label"] = label
item["publish_time"] = publish_time
item["tempy"] = tempy
item["discription"] = discription
item["loction"] = loction
return item
#去斜杠
def splits(self,value):
result =value.strip('/')
return result
def asks(self,value):
if '不限' in value:
start = 0
end = 0
elif '以下' in value :
res = self.num_pattern.search(value)
start = res.group()
end = res.group()
else:
res = self.num_pattern.findall(value)
start = res[0]
end = res[1]
return start,end
#统一日期格式
def times(self,value):
if ':' in value:
times=datetime.now().strftime('%Y-%m-%d')
elif '天前' in value:
res = self.num_pattern.search(value).group()
times = (datetime.now() - timedelta(days=int(res))).strftime('%Y-%m-%d')
else :
times = value
return times
|