Scrapy框架学习笔记-不止于python
1.Scrapy简介
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
- Scrapy 使用了 Twisted,其主要对手是Tornado,异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
2.Scrapy架构图(绿线是数据流向):
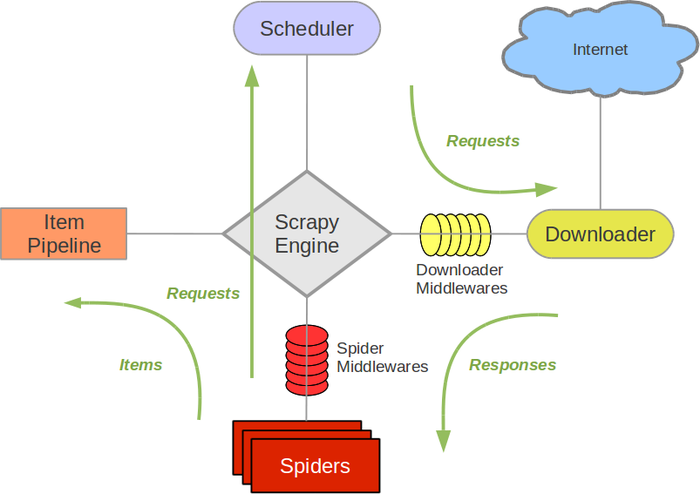
- Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
3. Scrapy 框架安装
Scrapy框架官方网址:https://doc.scrapy.org/
安装创建(windows)
1.pip install pypiwin32
2.pip install Scrapy (安装Scrapy框架)
注意:windows下可能需要手动安装twisted模块 如.whl: Twisted‑18.4.0‑cp35‑cp35m‑win_amd64.whl
下载地址: https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted (下载完成以后使用 pip install 安装就可以)
3. Scrapy 项目创建
1 | 1.打开指定创建项目的位置(文件夹下),按下shift键并右击鼠标,打开cmd命令行,输入 scrapy startproject 项目名称 |
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
4. 使用Scrapy框架编写简单的爬虫
以爬取百度为例:
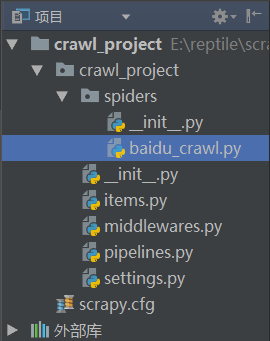
(1).在spiders文件夹下创建一个.py文件(文件名最好以爬取的网站为名)
以下为建完项目的目录:
代码如下:
1 |
1 | import scrapy |
1 |
|
1 |
1 | from scrapy import cmdline |
1 |
|
或者代开命令行,输入:scrapy crawl baidu (爬虫名称是创建.py爬虫文件里属性name的值,我这里是baidu)
注意:此处应该会失败。因为每个网站都有一个robots.txt,表示网站不允许爬的网站目录。scrapy框架遵守该协议。所以需要修改Scrapy框架的配置文件
在项目目录下的 settings.py 修改一下内容:
- ROBOTSTXT_OBEY = False # 默认是True
- 命令行下重新执行 scrapy crawl baidu
1 |
作者:
胖胖不胖
版权声明:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 不止于python
感谢您的支持,我会继续努力!

微信支付

支付宝
